Convert - FHIR (R4) to OMOP
POST /convert/v1/fhirr4toomop
This operation converts a FHIR R4 bundle (including one from CDA-to-FHIR, HL7-to-FHIR, or Combine Bundles) into the Observational Medical Outcomes Partnership (OMOP) Common Data Model format.
See the Analyzing with OMOP use case for more in-depth discussion of how to use this operation.
The input is a FHIR R4 bundle for a single patient.
Tip
If your FHIR bundle contains multiple FHIR Patient resources (all of which should be from the same person), use the
combine FHIR bundles operation prior to the OMOP conversion.
The output for the OMOP conversion is a ZIP archive, so specify accept: application/zip in your request header. The ZIP archive contains multiple Comma-Separated Value (CSV) files, one for each supported OMOP data table. See data tables for a complete list of contents.
Query Parameters
includePIITables
boolean
Specify true to include additional custom tables with more identifying details. See PII for details. Defaults to false.
omopVersion
string
Specify v54 (default) for OMOP CDM 5.4 or v53 for OMOP CDM 5.3.
personId
integer
Optional ID to be used in the OMOP person_id field. Defaults to 1.
Logging and Error Handling
If the input data is invalid (such as improperly-formatted FHIR data), the ZIP archive will not be created. Instead, the response will be a FHIR Operation Outcome in JSON format detailing the errors.
However, in many cases the Convert service can continue processing even when there are issues with the input data, such as missing fields or unexpected data types. In such cases, issues are reported in a custom extension table named PROCESSING_LOG.csv. This processing log categorizes issues as:
- Informational - Basic information about the data processing, e.g., added a medication.
- Warning - The service had to modify the record due to a problem, e.g., a string was truncated because it exceeded the maximum length.
- Error - The service rejected some data because of an unrecoverable problem, e.g., a required field was missing.
Note
Data rows with issues categorized as Error are omitted from the final output.
The Convert service uses v5.4 of the OMOP Common Data Model (CDM) specification, with a few exceptions described in Processing Notes and a few custom extension tables.
You can alternately request CDM v5.3 using the omopversion query parameter, as described in Inputs and Outputs.
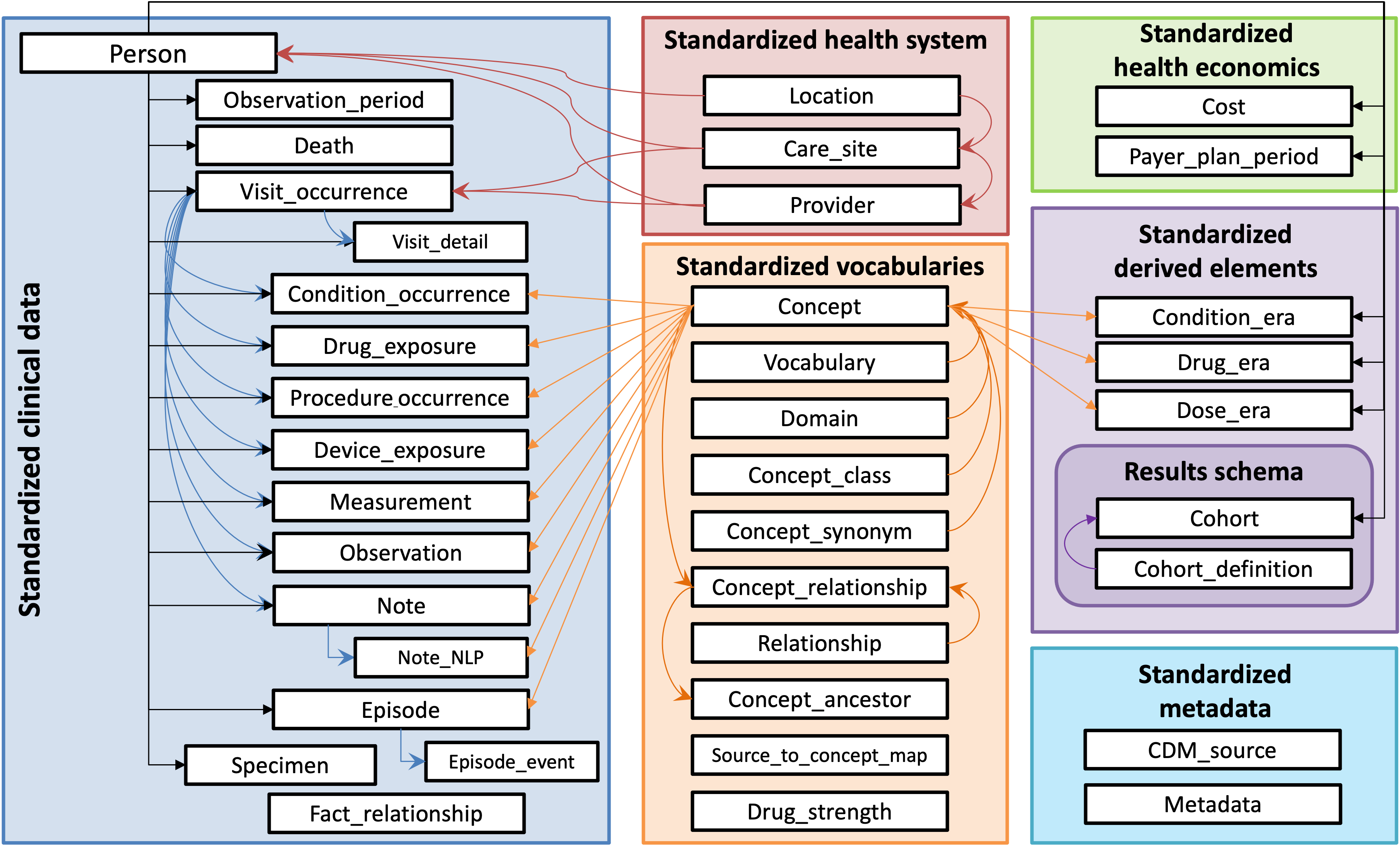 OMOP Common Data Model (source: OHDSI)
OMOP Common Data Model (source: OHDSI)
Custom Extension Tables
Since the mapping between FHIR and OMOP is not 1-1, any system that automatically transforms data between the two standards has to make compromises. The Convert API includes several custom extension tables to assist in tracing data lineage in order to understand how the FHIR data maps to OMOP tables.
DATA_SOURCE
The DATA_SOURCE table ties together OMOP rows with the FHIR resources that originated them.
For example, assume the DRUG_EXPOSURE table includes a row with a diagnosis of mitral stenosis:
| drug_exposure_id |
drug_concept_id |
drug_source_value |
| 1000002 |
40213230 |
115 tetanus toxoid, reduced diphtheria toxoid |
The DATA_SOURCE table shows that the drug exposure originated from a specific FHIR Immunization resource:
| table_name |
fk_id |
path |
| DRUG_EXPOSURE |
1000002 |
Immunization/9.522caeea7d5e466e8c44b9bf87e37e34 |
SOURCE_CODING
The SOURCE_CODING table helps you understand the terminology anlaysis that led to selecting a particular OMOP concept.
For example, assume the CONDITION_OCCURRENCE table includes a condition row with an OMOP concept ID:
| condition_occurrence_id |
condition_source_value |
condition_source_concept_id |
| 1000001 |
0261 Streptobacillary fever |
44833220 |
The SOURCE_CODING table can illuminate how the Convert API decided on those values, tying it to a specific source code in the original FHIR data:
| table_name |
fk_id |
source_system |
source_code |
source_display |
| CONDITION_OCCURRENCE |
1000001 |
2.16.840.1.113883.6.103 |
261 |
Streptobacillary fever |
PROCESSING_LOG
The PROCESSING_LOG contains a detailed log of the FHIR resource processing. In particular, it notes errors and warnings when there are issues with the input data. See Logging and Error Handling for more details.
Some example messages:
| level |
code |
text |
| Information |
RowCreated |
Created PERSON.1 from Patient/811e7ddb-be81-4379-8a1e-53ab907dcb58 |
| Information |
RowCreated |
Created VISIT_OCCURRENCE.1000001 from Encounter/075061a1-1879-4802-ba1a-cc7cba78a445 |
| Information |
ValueTruncated |
Truncated DRUG_EXPOSURE.drug_source_value value, length is greater than 50. Original value: 00006-4943-00 pneumococcal polysaccharide vaccine, 23 valent |
| Warning |
FhirProcessingIssue |
The needed Immunization field ‘doseQuantity’ is missing (Immunization/9.522caeea7d5e466e8c44b9bf87e37e34) |
| Error |
DuplicateFhirElement |
Dropped 2 duplicate resources Encounter/075061a1-1879-4802-ba1a-cc7cba78a445,Encounter/075061a1-1879-4802-ba1a-cc7cba78a445,Encounter |
For a full list of processing codes, see OMOP Processing Code System.
Processing Notes
There are several nuances involved in converting data from FHIR to OMOP, discussed below.
Identifiers
FHIR uses string types for its identifiers, but OMOP uses integers. To account for this, the Convert API assigns integer IDs to the OMOP table entries, and maintains a mapping table between these IDs and their FHIR origins.
person_id in the PERSON table can be specified via the personId query parameter, or will default to 1.- In all other tables, the entries will be assigned sequential identifiers automatically. The base for these identifiers is
person_id * 1,000,000.
For example: if the person_id is 1,234, the first observation_id in the OBSERVATION table will be 1,234,000,001, the second will be 1,234,000,002, etc. These identifiers are not globally unique, so the first provider_id in the PROVIDER table will also be 1,234,000,001.
To trace an entry back to its FHIR resource, use the DATA_SOURCE table. For example, this could show you that OBSERVATION 1,234,000,001 originated from FHIR resource Observation/2.0416a4c955144ee586c76199ea41bf79 or that PROVIDER 1,234,000,001 originated from the FHIR resource Practitioner/c21cf630-5689-4a46-987f-f748994c7b2d.
Data Types
With the exception of ID fields (mentioned above), the Convert service will enforce the data types defined in the OMOP standard. When importing OMOP data into a database, ensure your schema aligns with those data types.
Primary Keys
The Convert service will enforce primary and foreign key references (including concept_ids, which should reference standard OMOP concepts as of export time).
Lossiness
By the nature of the specification, OMOP is lossy. It focuses on standard, validated data most suitable for analysis, and assumes that any necessary data cleanup has been performed prior to OMOP export. Rows containing errors are dropped from the output, as described in error handling.
PII
OMOP does not include names and patient identifiers (such as SSN or MRNs) from the FHIR input, though it does include personally-identifiable information like date of birth.
Pass the query parameter includePIITables with a value of true to export additional custom tables with more identifying information. These tables let you associate details like names, addresses, and emails with OMOP person identifiers.
These extra PII tables include:
- pii_address.csv
- pii_email.csv
- pii_mrn.csv
- pii_name.csv
- pii_phone_number.csv
Concepts and Vocabularies
As part of the OMOP conversion, the Convert service will attempt to match coded values within the bundle to corresponding concepts from OMOP’s Standard Vocabularies, and populate several potential fields for each data row:
- The main concept ID (e.g.,
condition_concept_id or observation_concept_id) will contain the corresponding OMOP concept ID if the concept is designated standard. If no standard concept was found, this will be set to a concept ID of 0 (“no matching concept”).
- The source concept ID (e.g.,
condition_source_concept_id or procedure_source_concept_id) will contain the corresponding OMOP concept ID if the concept is designated non-standard.
- The source value (e.g.,
condition_source_value or procedure_source_value) will contain a string value that combines the original source code and display name.
For example, a condition was originally coded with the ICD-10 code J45.5 (severe persistent asthma). the Convert service finds a corresponding OMOP concept 45591559, which is non-standard. OMOP contains a cross-walk mapping from 45591559 to the standard OMOP concept 4145356. Thus, the data will be:
| Field |
Value |
condition_concept_id |
4145356 (standard) |
condition_source_concept_id |
45591559 (non-standard) |
condition_source_value |
J45.5 severe persistent asthma (original) |
Domains and Data Tables
OMOP requires that certain domains go into specific data tables, which may differ from their original FHIR resource. For example, a FHIR Procedure may be placed into the OMOP MEASUREMENT table rather than the PROCEDURE_OCCURRENCE table.
Example
FHIR Bundles and OMOP contents are verbose, so the example below just shows a small sample to illustrate how the data is structured. For a more complete example, try out the API in the Developer Portal Sandbox.
Sample Input
{
"resourceType": "Bundle",
"type": "batch-response",
"entry": [
{
"resource": {
"resourceType": "Patient",
"id": "35b77437-425d-419c-90b5-af4bc433ebe9",
... (patient fields)
}
},
{
"resource": {
"resourceType": "Procedure",
"id": "7.2ed0fe30094a46e7bf6b3ebe69ead24a",
... (encounter fields)
}
},
{
"resource": {
"resourceType": "Procedure",
"id": "7.14e26bb09d7649b2a6ce10f794ca8960",
... (encounter fields)
}
},
...
]
}
Sample Output
PERSON.csv:
person_id,gender_concept_id,year_of_birth,month_of_birth,day_of_birth,birth_datetime,race_concept_id,ethnicity_concept_id,location_id,provider_id,care_site_id,person_source_value,gender_source_value,gender_source_concept_id,race_source_value,race_source_concept_id,ethnicity_source_value,ethnicity_source_concept_id
Patient/35b77437-425d-419c-90b5-af4bc433ebe9,8532,1956,8,13,1956-08-13T00:00:00.0000000,0,0,,,,35b77437-425d-419c-90b5-af4bc433ebe9,female,,,,,
OBSERVATION.csv:
observation_id,person_id,observation_concept_id,observation_date,observation_datetime,observation_type_concept_id,value_as_number,value_as_string,value_as_concept_id,qualifier_concept_id,unit_concept_id,provider_id,visit_occurrence_id,visit_detail_id,observation_source_value,observation_source_concept_id,unit_source_value,qualifier_source_value,value_source_value,observation_event_id,obs_event_field_concept_id
Procedure/7.2ed0fe30094a46e7bf6b3ebe69ead24a,Patient/35b77437-425d-419c-90b5-af4bc433ebe9,0,2009-07-01,2009-07-01T12:00:00.0000000,32817,,,,,,,,,465 Treatment for Upper Respiratory Infection,,,,,,
Procedure/7.14e26bb09d7649b2a6ce10f794ca8960,Patient/35b77437-425d-419c-90b5-af4bc433ebe9,0,2009-06-07,2009-06-07T20:30:00.0000000,32817,,,,,,,,,OtherThymusOperations Oth thorac op thymus NOS,,,,,,
etc.